
Market Basket Analysis
Market Basket Analysis (MBA) is the process to identify customers buying habits by finding associations between the different items that customers place in their “shopping baskets”. This analysis is helpful for retailers or E-Commerce to develop marketing strategies by gaining insight into which items are frequently bought together by customers. 
- Introduction
- The Dataset
- EDA
- Apriori Algorithm
- Determining Rules
- Interpreting Metrics
- Findings and Conclusions
Introduction
Market Basket Analysis (MBA) is a data mining technique that is use to identify customers buying habits by finding associations between the different items that customers place in their “shopping baskets”. When used appropriately, MBA can be an effective tool for business in understanding consumer behavior better and influence it.
For example, if customers are buying cookies, how probably are they to also buy milk in the same transaction. This information may lead to increase sales by helping the business by doing product placement, shelf arrangements, up-sell,cross-sell, and bundling opportunities.
There are multiple algorithms that can be used in MBA to predict the probability of items that are bought together.
- AIS
- SETM Algorithm
- Apriori Algorithm
- FP Growth
In this project I would be exploring the Apriori Algorithm.
The Dataset
The groceries dataset was published in 2020 and can be download in Kraggle.The dataset has 38765 rows of the purchase orders of people from the grocery stores. These orders can be analysed and association rules can be generated using Market Basket Analysis by algorithms like Apriori Algorithm.
EDA
In this section we will be reading the dataset and doing some exploratory data analysis
# Import Libaries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
# you might need to pip install mlxtend to import the libraries below
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
from mlxtend.preprocessing import TransactionEncoder
from mpl_toolkits.mplot3d import Axes3D
import networkx as nx
from datetime import datetime, timedelta
from dateutil.parser import parse
#import and read the dataset
df_basket = pd.read_csv("Groceries_dataset.csv")
df_basket.head(10)
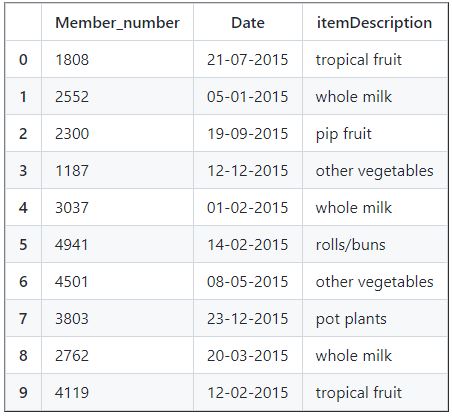
Before applaying any algoriths or machine learning techniques, it is important to understand our dataset.
- Check the shape of the dataset
- Check the data type in each column
- Check for any null values
- Check for duplicate entries
- Plot insight related to our problem
#Check the shape of the dataset
df_basket.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 38765 entries, 0 to 38764
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Member_number 38765 non-null int64
1 Date 38765 non-null object
2 itemDescription 38765 non-null object
dtypes: int64(1), object(2)
memory usage: 908.7+ KB
The .info function is really useful to getting a quick overview of the dataset. This answer the following questions for our EDA:
- The dataset contains 38764 rows and 3 columns
- We have two columns with intergers data type and one with object
- we have Zero null values
- The
datecolumn have is in objective we should change this to Date format.
#convert to colunm date o date format
df_basket.Date = pd.to_datetime(df_basket.Date)
df_basket.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 38765 entries, 0 to 38764
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Member_number 38765 non-null int64
1 Date 38765 non-null datetime64[ns]
2 itemDescription 38765 non-null object
dtypes: datetime64[ns](1), int64(1), object(1)
memory usage: 908.7+ KB
#Double Checking for Null Values
df_basket.isnull().sum()
Member_number 0
Date 0
itemDescription 0
dtype: int64
#Let's take a look at unique values
df_basket.nunique()
Member_number 3898
Date 728
itemDescription 167
dtype: int64
We can observe the following:
- we have 167 unique items
- total of 3898 unique customers
#let check for duplicate rows
df_basket.duplicated().sum()
759
The dataset have a total of 759 duplicate rows. Lets drop this rows.
# drop duplicates
df_basket = df_basket.drop_duplicates()
#check the shape of the dataset
df_basket.shape
(38006, 3)
This Dataset was mostly clean and it didn’t need to much cleaning. Now we can do some plotting to get some insights.
""""For plotting purpuses,I'm going to create use datetime series and creat colunms of for day of week, days, month, year"""
# copy data frame, using copy would allow us to refer to the orginal dataset later.
df_time = df_basket.copy()
# create index for time
df_time.index = df_time["Date"]
#add colunms
df_time['date']=df_time["Date"]
df_time['day']=df_time.index.day
df_time['Week']=df_time.index.week
df_time['Month']=df_time.index.month
df_time['Year']=df_time.index.year
#drop Date colunm
df_time = df_time.drop("Date", axis=1)
#check the data set
df_time
#get days of the week
df_time['weekday'] = df_time['date'].apply(lambda x: parse(str(x)).strftime("%A"))
df_time
#get the number average of transaction ped month
df_time[['date',"itemDescription"]].groupby('date').count().resample('M').mean().plot()
plt.xlabel("Year", fontsize=10)
plt.ylabel("Count of Transactions", fontsize=10)
plt.title("Average of Transactions per Year by Month", fontsize=14);
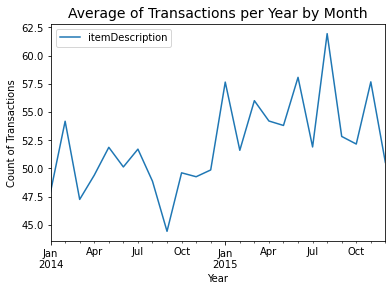
| We can observe that business is doing well as their is a trend of transactions been increase over time. | The graph above can help us gain some insight in seasonality. for example, it looks like October trend to be a slower month. |
#plot counts of transaction per year
fig,ax = plt.subplots()
sns.countplot(data=df_time,x="Year")
ax.set(xlabel='Year',title="Number of Transactions per Year");
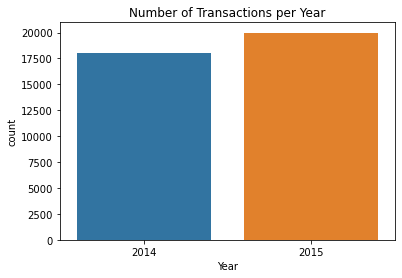
2015 have better sales that 2014.
#plot counts of transaction for day of the Week
fig,ax = plt.subplots()
fig.set_size_inches(10,5)
sns.countplot(data=df_time,x="weekday")
ax.set(xlabel='Day',title="Transactions per day of the week");
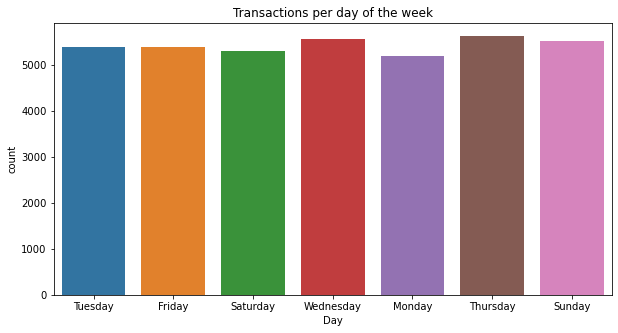
It looks like Wednesday, Thursday, and Sundays are the busiest days. It is important for the business to be well stock in inventory and have full staff during these days.
#plot top 10 products
fig,ax = plt.subplots()
fig.set_size_inches(15,5)
sns.countplot(data=df_time,x="itemDescription",order=df_time.itemDescription.value_counts().iloc[:10].index)
ax.set(xlabel='Products',title="Top 10 products");
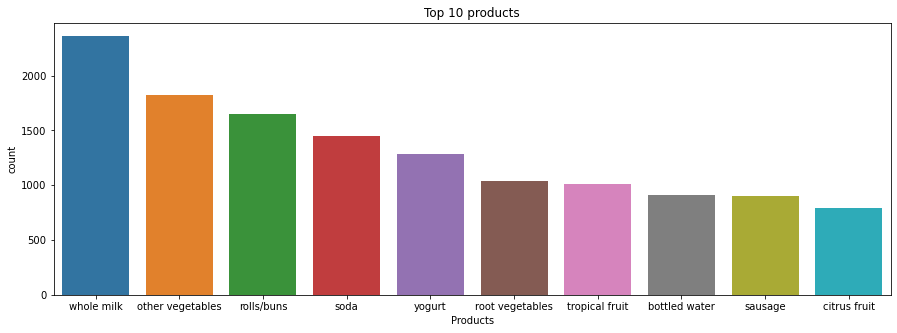
Understanding the top 10 sellers is beneficial to make sure the business is well stock of this products. In addition, this can be main drivers for people to walk in to a store so they can use this to their advantage to cross sell with other products, improve product placement, and bundling opportunities.
#plot 10 low selling products
fig,ax = plt.subplots()
fig.set_size_inches(18,5)
sns.countplot(data=df_time,x="itemDescription",order=df_time.itemDescription.value_counts().iloc[-10:].index)
ax.set(xlabel='Products',title="Worst 10 products");
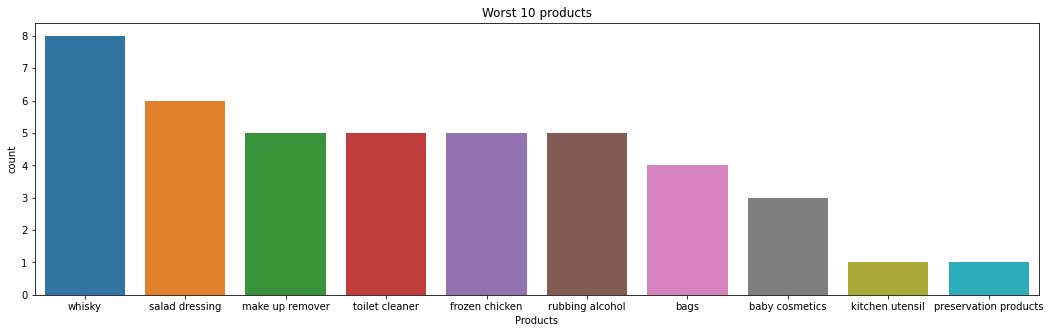
It is important to understand low selling products. We might be able to increase the sales of this product by doing a proper basket analysis. In addition, Business can investigate further if is profitable to carrier these products.
#plot top 20 customers
fig,ax = plt.subplots()
fig.set_size_inches(18,5)
sns.countplot(data=df_time,x="Member_number",order=df_time.Member_number.value_counts().iloc[:20].index)
ax.set(xlabel='Customer ID',title="Top 20 Customers");
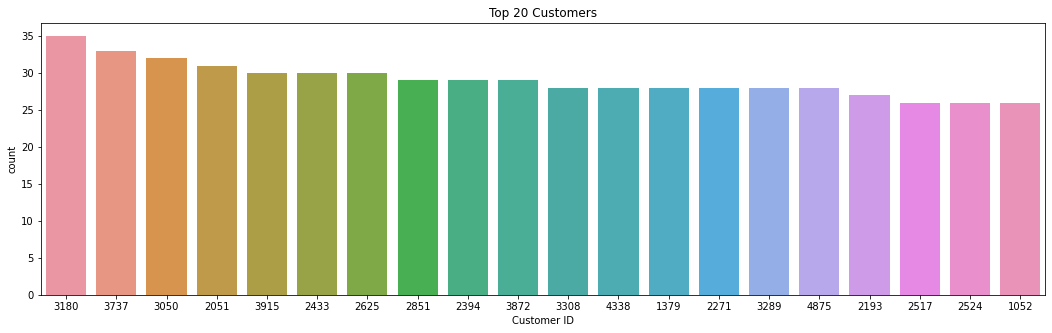
From the plot above we can observe that top costumers tend two have a total of 35 -30 transaction from 2014 to 2015.
Apriori Algorithm
To do the Market Basket analysis i would use the Apriori Algorithm. I won’t get into any detail for the math behind the algorithm.Wikipedia has the exact details on how it works.
In the dataset, we can observe that each transaction item is record separately. For example, when a customer buy Whole Milk and Cookies it is recorded on the dataset as two rows.
In order to do a market basket analysis it is important to group all the items that where purchase on the same transaction together. The best way to do this is by grouping the items by customer number and date.I would go back to my original Data Frame (df_basket)
items = df_basket.groupby(['Member_number', 'Date']).agg({'itemDescription': lambda x: x.ravel().tolist()}).reset_index()
items.head()
items.shape
(14963, 3)
# Import the transaction encoder function from mlxtend
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
# Instantiate transaction encoder and identify unique items in transactions
transactions = items["itemDescription"]
encoder = TransactionEncoder().fit(transactions)
# One-hot encode transactions
onehot = encoder.transform(transactions)
# Convert one-hot encoded data to DataFrame
onehot_basket = pd.DataFrame(onehot, columns = encoder.columns_)
# Print the one-hot encoded transaction dataset
onehot_basket.head()
onehot_basket.shape
(14963, 167)
Determining Rules
Once our data is in the format above, we can begin to determine association rules.
Here, we calculate several metrics to analyse the rules. These are calculated automatically by the package, but we will take time to understand them.
First, all of our groups are designated as ‘antecedents’ and ‘consequents’. This allows us to say: ‘given this group of antecedents, we see this group of consequents with frequency x’. We will designate antecedents as 𝑋 and consequents as 𝑌 below.
Let’s make some rules for illustration of these measures:
from mlxtend.frequent_patterns import association_rules
"""" we don't have a large enough dataset, so i only used .02 for support.
For simplicity I used only a max_len of 2, if you want to see more than two
items you can channge this rule"""
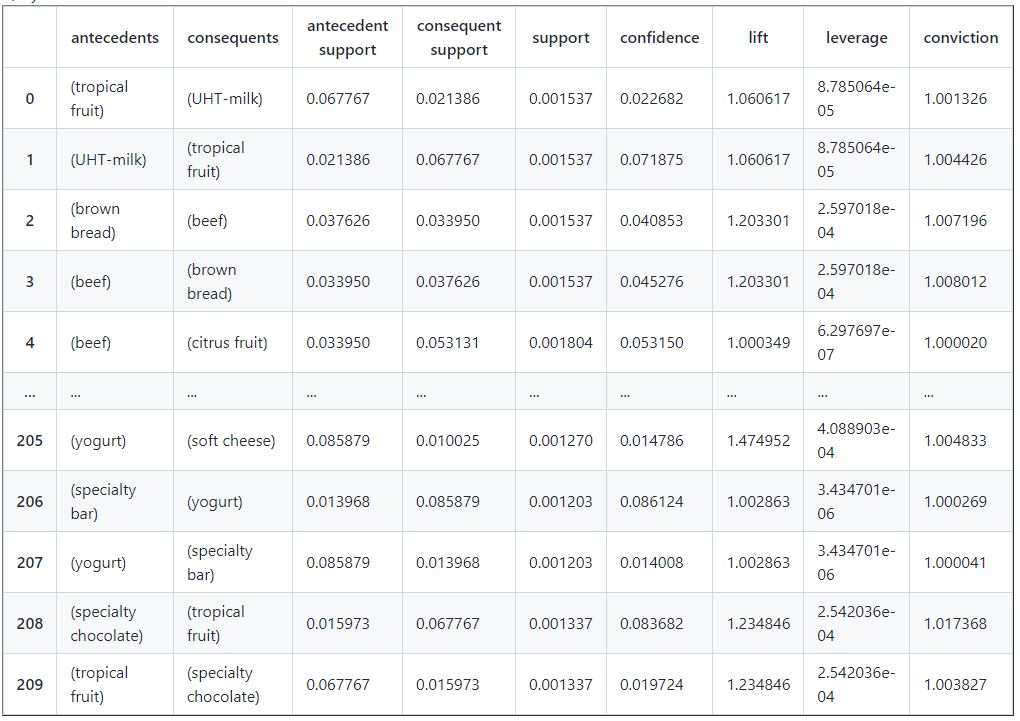
x = apriori(onehot_basket, min_support=.001,max_len=2,use_colnames=True)
#take a look at the help for ways we can use this function
df_rules = association_rules(x, metric="lift", min_threshold=1)
#take a look
df_rules
Interpreting Metrics
We have a lot of of metrics in the data frame above and is important to understand this metrics and how to get insight from it.
Support allows us to see how often the basket occurs. We don’t want to waste our time promoting strong links between items if only a few people buy them.
Confidence allows us to see the strength of the rule. What proportion of transactions with our first item also contain the other item (or items)? For example, how true are both items (beef and brown bread) occurred in a transaction together
Lift can be interpreted a measure of how much we potentially drive up the sales of the consequent by the relationship? In theory it can be seen as proportional to the increase of sales of the antecedent. For any value higher than 1, lift shows that there is actually an association Higher Values has generally stronger association
Additional Association Rules: Leverage and Conviction are less common options for assessing the strength of the co-occurrence relationship.
Leverage computes the difference between the observed frequency of X and Y appearing together and the frequency that would be expected if X and Y were independent. A leverage value of 0 indicates independence.
The rationale in a sales setting is to find out how many more units (items X and Y together) are sold than expected from the independent sales.
Conviction looks at the ratio of the expected frequency that the rule makes an incorrect prediction if X and Y were independent, divided by the observed frequency of incorrect predictions.This is how strongly consequents depend on antecedent. For example, if a customer does not buy beef, they will not buy brown bread.
Let’s take a look at some insight by products by sorting the top 5 items that are shop together
#sort the rules by support
df_rules.sort_values(by='support',ascending = False).head()
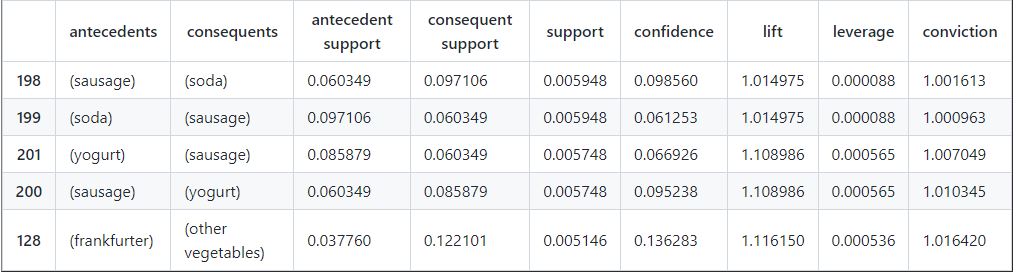
The product sausage an soda are the items with the higher support. Lets take a look Sausage to gain more this insight can be applied to any products but for simplicity I will only do one.
#Sort the dataset
sausage_insight = df_rules[df_rules['consequents'].astype(str).str.contains('sausage')]
sausage_insight = milk_insight.sort_values(by=['lift'],ascending = [False]).reset_index(drop = True)
sausage_insight.head()
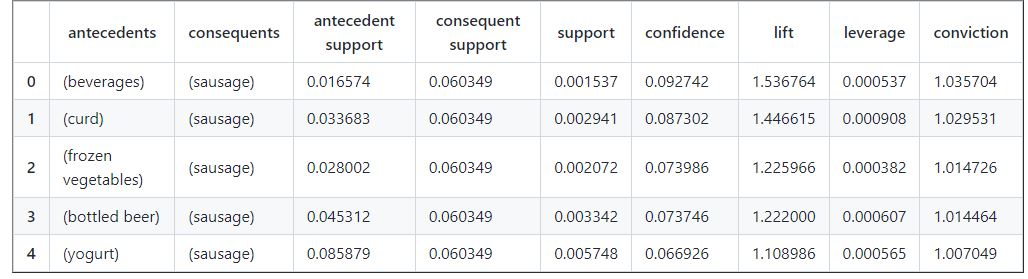
We can observe that beverage,curd,frozen vegetables,bottled beer, and yogurt drive the sales of sausage. Running promos and discount on these items can increase sales for sausages. This can be good insight if sausages are at the end of life and the stores want to get rid of them.
df
df_rules.sort_values(by=['lift'],ascending = [False]).reset_index(drop = True).head(10)
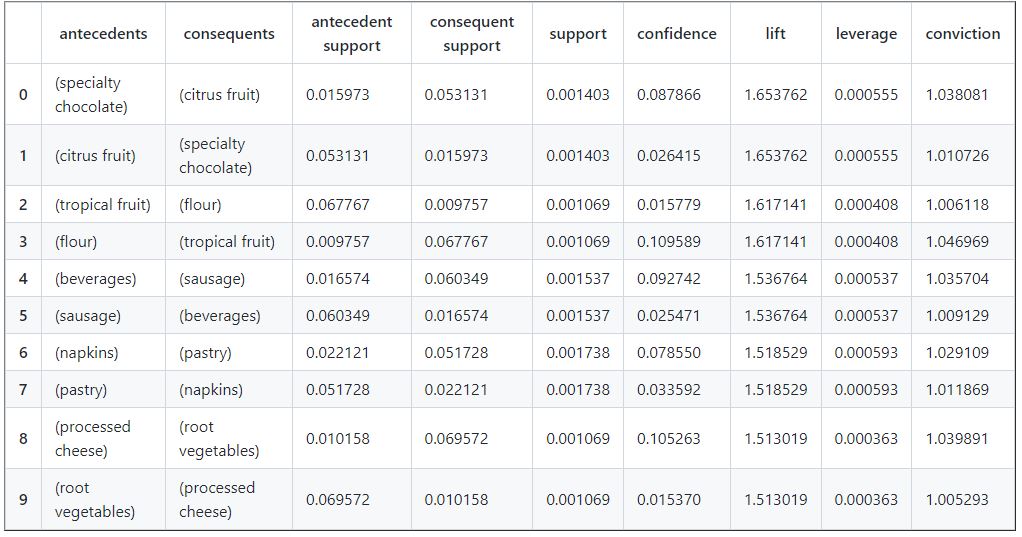
Lastly, I want to get insight of the products that have a high confidence and the highest lift scores.
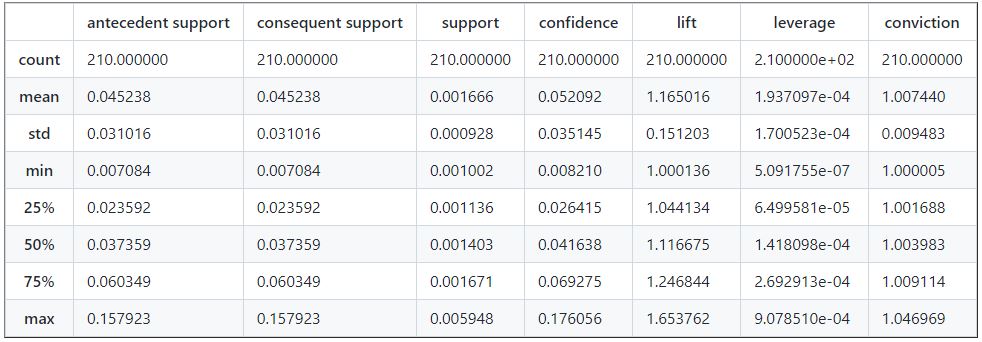
# lets check some basic stats of our rules.
df_rules.describe()
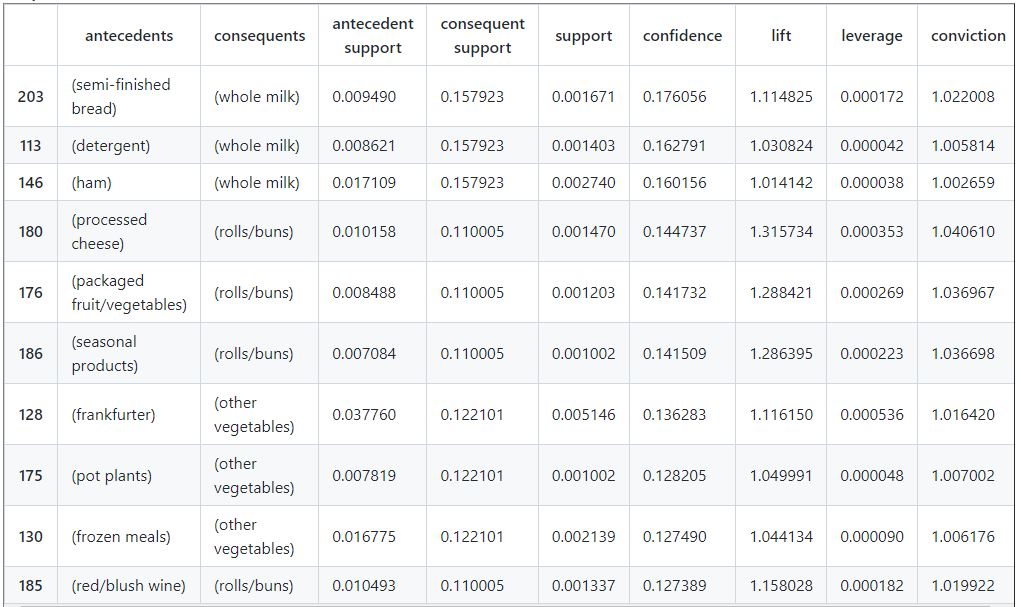
#sort by confidence and then lift
df_rules.sort_values(['confidence', 'lift'], ascending=[False,False ], inplace=True)
df_rules.head(10)
Findings and Conclusions
From the above we can observe the following:
- Whole milk, rolls/buns and other vegetables tend to be frequently add on items.
- We can place consequent items if possible next to the antecedent items to drive sales.
- For items that can be place next to each other , like detergent and whole milk we can make sure that the layout of the stores are close to each others. .
Using Apriori algorithm is a very useful technique to find associations between items. In addition, They are easy to implement and explain. However for more complex insights, such as the ones been used by Amazon, Google, Netflix we can use recommendation systems.